

一分彩app下载 进入AI应用期间,CPU有望成为下一个“存储”机遇吗?


在算力需求暴增的今天,CPU是否会重演PC期间崛起外传?这是一个值得想考的问题。如今,大模子推理、端侧AI、智能物联网正将计较压力推向新的临界点。英特尔、AMD股价悄然攀升,Arm架构异军突起,致使连苹果、小米齐在自研芯片中加大CPU进入。
这究竟是已而的风口,如故结构性机遇的运转?当云表集群的CPU诈骗率面对红线,当每台终局开导齐需要寂寥的AI推理武艺,传统处理器是否仍是站在爆发的边际?
推理有望成为闭塞标的
跟着AI应用从实验室走向千行百业,推理计较正取代磨真金不怕火成为AI算力的主战场。据IDC与海浪信息聚积估计,2023年中国AI办事器责任负载中磨真金不怕火端占比58.7%,而到2027年推理端算力需求将飙升至72.6%。当大模子逐步老到,企业对算力的需求不再是砸钱堆叠磨真金不怕火集群,而是怎样将模子高效、经济地部署到着实业务场景中。这种转机,让CPU这一传统通用处理器从头站在了舞台中央。
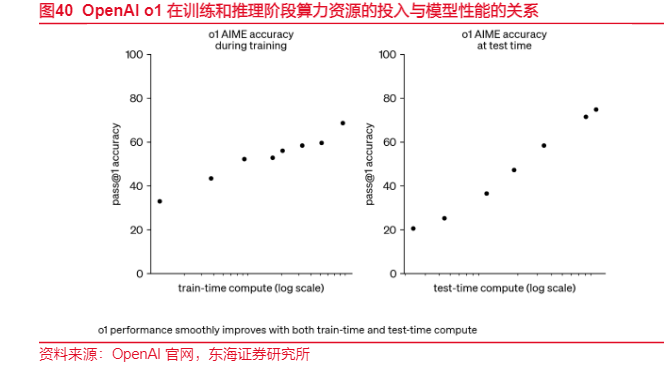
在推理场景中,CPU的性价比上风正被从头发现。与动辄数十万、功耗惊东说念主的GPU相比,CPU在资本、可用性和总领有资本(TCO)上展现出无可比较的竞争力。英特尔数据高慢,使用CPU进行AI推理无需构建新的IT基础要领,可复用既有平台稳重算力,幸免异构硬件带来的管制复杂度。更闭塞的是,通过AMX加快、INT8量化优化等技艺,当代CPU的推感性能已竣工质的飞跃。实测标明,经由优化的至强处理器在ResNet-50等模子上推理速率擢升可达8.24倍,精度蚀本不及0.17%。这种形态,正中中小企业下怀——它们不需要GPT-4级别的算力,但需要能跑通32B参数模子的经济型有策画。
CPU的用武之地,碰巧集结在AI推理的"长尾商场"。第一类是小谈话模子(SLM)部署,如DeepSeek-R1 32B、Qwen-32B等模子,它们在企业级场景华文武艺隆起,参数领域适中,米兰app官网版CPU完好意思能够胜任。第二类是数据预处理与向量化法子,这类任务波及文本清洗、特征索求、镶嵌生成等,自然合适CPU的串行处理武艺。第三类是并发量高但单次计较浮浅的"长尾"推理任务,如客服问答、内容审核等,CPU可通过多中枢并行处理数百个轻量级肯求,竣工更高的隐隐率。这些场景的共同点是:对蔓延条件相对宽松,但对资本相当敏锐,恰是CPU有所四肢的舞台。
2025年以来的很多上市公司仍是将相干居品推向商场。海浪信息(000977) 在3月领先推出元脑CPU推理办事器NF8260G7,搭载4颗英特尔至强处理器,通过张量并行和AMX加快技艺,单机可高效运行DeepSeek-R1 32B模子,单用户性能超20 tokens/s,同期处理20个并发肯求。神州数码(000034) 则在7月的WAIC大会上发布KunTai R622 K2推理办事器,基于鲲鹏CPU架构,一分彩app在2U空间内维持4张加快卡,主打"高性能、低资本"门道,对准金融、运营商等预算敏锐型行业。这些厂商的布局揭示了一个明战胜号:CPU推理不是退而求其次,而是主动政策遴荐。
{jz:field.toptypename/}更深层的逻辑在于,AI算力正在走向"去中心化"和"场景化"。当每个工场、每家病院致使每个手机齐需要镶嵌式推理武艺时,不成能也无用要一齐依赖GPU集群。CPU四肢通用算力底座,能够将AI武艺无缝融入现存IT架构,竣工"计较即办事"的平滑过渡。在这个意料上,CPU果然正在成为AI期间的"新存储":它不是最精明的,但却是不成或缺的算力基础要领。
CPU 可能比 GPU 更早成为瓶颈
在Agent驱动的强化学习(RL)期间,CPU的瓶颈效应正以比GPU清寒更荫藏却更致命的形势显露。与传统单任务RL不同,当代Agent系统需要同期运行成百上千个寂寥环境实例来生成磨真金不怕火数据,这种"环境并行化"需求让CPU成为事实上的第一块短板。
2025年9月,蚂汇集团开源的AWORLD框架将Agent磨真金不怕火解耦为推理/实施端与磨真金不怕火端后,被动接管CPU集群承载海量环境实例,而GPU仅认真模子更新。这种架构遴荐并非假想偏好,而是环境计较密集型的势必戒指——每个Agent在与操作系统、代码讲明注解器或GUI界面交互时,齐需要寂寥的CPU程度进事业态管制、动作证实和奖励计较,导致中枢数成功决定了可同期探索的轨迹数目。
更深层的矛盾在于CPU-GPU pipeline的异步失衡。当CPU侧的环境模拟速率无法匹配GPU的推理隐隐量时,policy lag(策略滞后)急剧恶化——GPU被动空转恭候训戒数据,而Agent正在学习的策略与收罗数据时的旧策略之间产生致命时差。这种滞后不仅缩小样本恶果,更在PPO等on-policy算法中激发磨真金不怕火颤动,致使导致策略发散。智元机器东说念主2025年3月开源的VideoDataset样貌印证了这小数:其CPU软件解码有策画成为磨真金不怕火瓶颈,切换到GPU硬件解码后隐隐量擢升3-4倍,CPU诈骗率才从饱和现象回落。
2025年的工业级执行进一步高慢了CPU瓶颈对拘谨强健性的系统性破损。腾讯的AtlasTraining RL框架在万亿参数模子磨真金不怕火中,不得不很是假想异构计较架构来调和CPU与GPU的互助,因其发现环境交互的随即种子、CPU中枢革新策略的轻微各异,领略过早期学习轨迹的蝴蝶效应影响最终策略性能。更严峻的是,多智能体强化学习(MARL)的非隆重性加重了这一问题——当数百个Agent策略同步更新时,CPU不仅要模拟环境,还需及时计较聚积奖励、调和通讯,这成功导致现象空间复杂度呈指数级增长。
内容上,Agent RL将计较范式从"模子密集"转向"环境密集",而CPU恰是环境模拟的物理载体。当Agent需要探索用具使用、长链推理等复杂行径时,每个环境实例齐是一个袖珍操作系统,花消1-2个CPU中枢。此时,进入再多的A100或H200,若CPU中枢数不及,GPU诈骗率仍会在30%以下踯躅,拘谨时辰从数周延长至数月。
2025年,这种瓶颈已从学术盘考扩张至产业执行,责罚CPU瓶颈已成为RL infra的中枢战场。Agent期间的算力竞赛,输赢手卤莽不在GPU的峰值算力,而在于能否用满盈的CPU中枢喂饱那些饥饿的智能体。
 备案号:
备案号: